
4-一致性哈希(Go实现分布式缓存)
一致性哈希
普通hash算法
普通的hash算法在分布式应用中的不足
在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%N,key是数据的哈希值,N是服务器节点数。
如果有一个节点加入或退出这个集群,也就意味着几乎缓存值对应的节点都发生了改变。即几乎所有的缓存值都失效了。节点在接收到对应的请求时,均需要重新去数据源获取数据,容易引起 缓存雪崩。
一致性哈希
一致性哈希原理
哈希算法是对节点的数量进行取模运算,而一致性哈希是对2^32进行取模运算。一致性哈希将整个哈希值空间组成一个虚拟的圆环,也就是哈希环。
- 计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
- 计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。
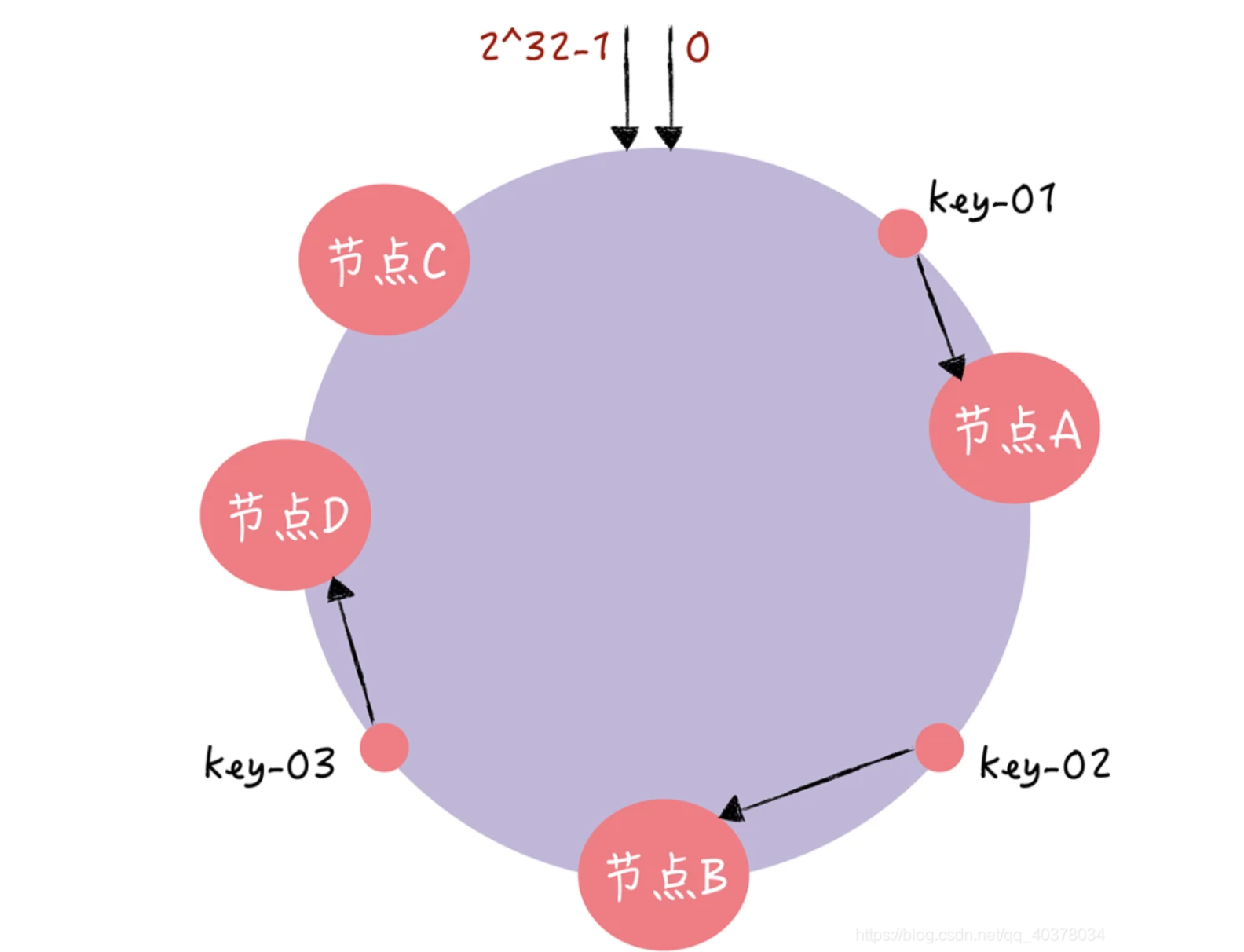
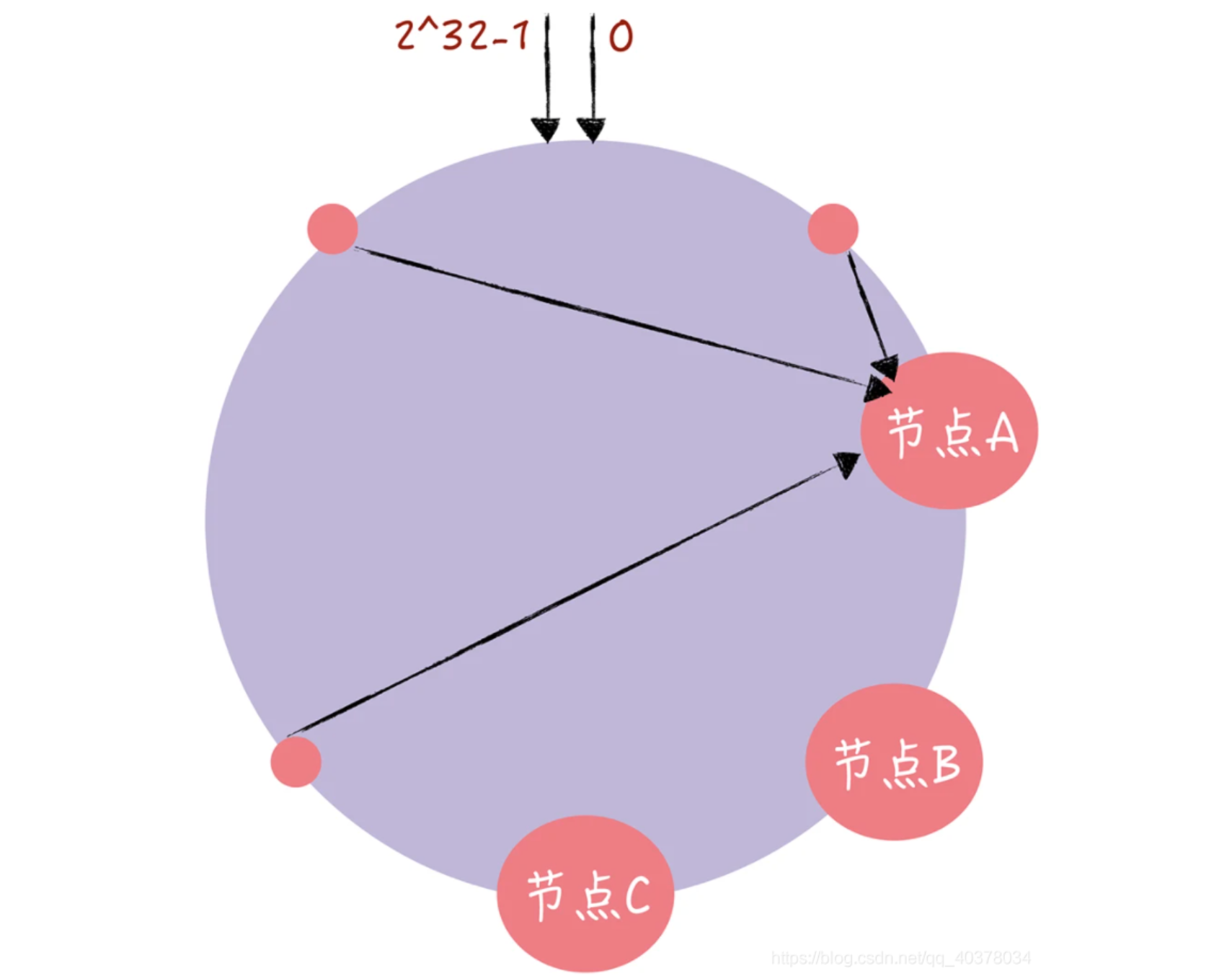
在一致性哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是会寻址到此节点和前一节点之间的数据。
一致性哈希数据倾斜
在一致性哈希算法中,如果节点太少,容易因为节点分布不均匀造成数据访问的冷热不均,也就是说大多数访问请求都会集中少量几个节点上。
通过引入虚拟节点解决分布不均匀的问题。对每一个服务器节点计算多个哈希值,每个计算结果位置上都放置一个虚拟节点,并将虚拟节点映射到实际节点。比如,可以在主机名后面增加编号,分别计算Node-A-01、Node-A-02、Node-B-01、Node-B-02、Node-C-01、Node-C-02的哈希值,于是形成6个虚拟节点。
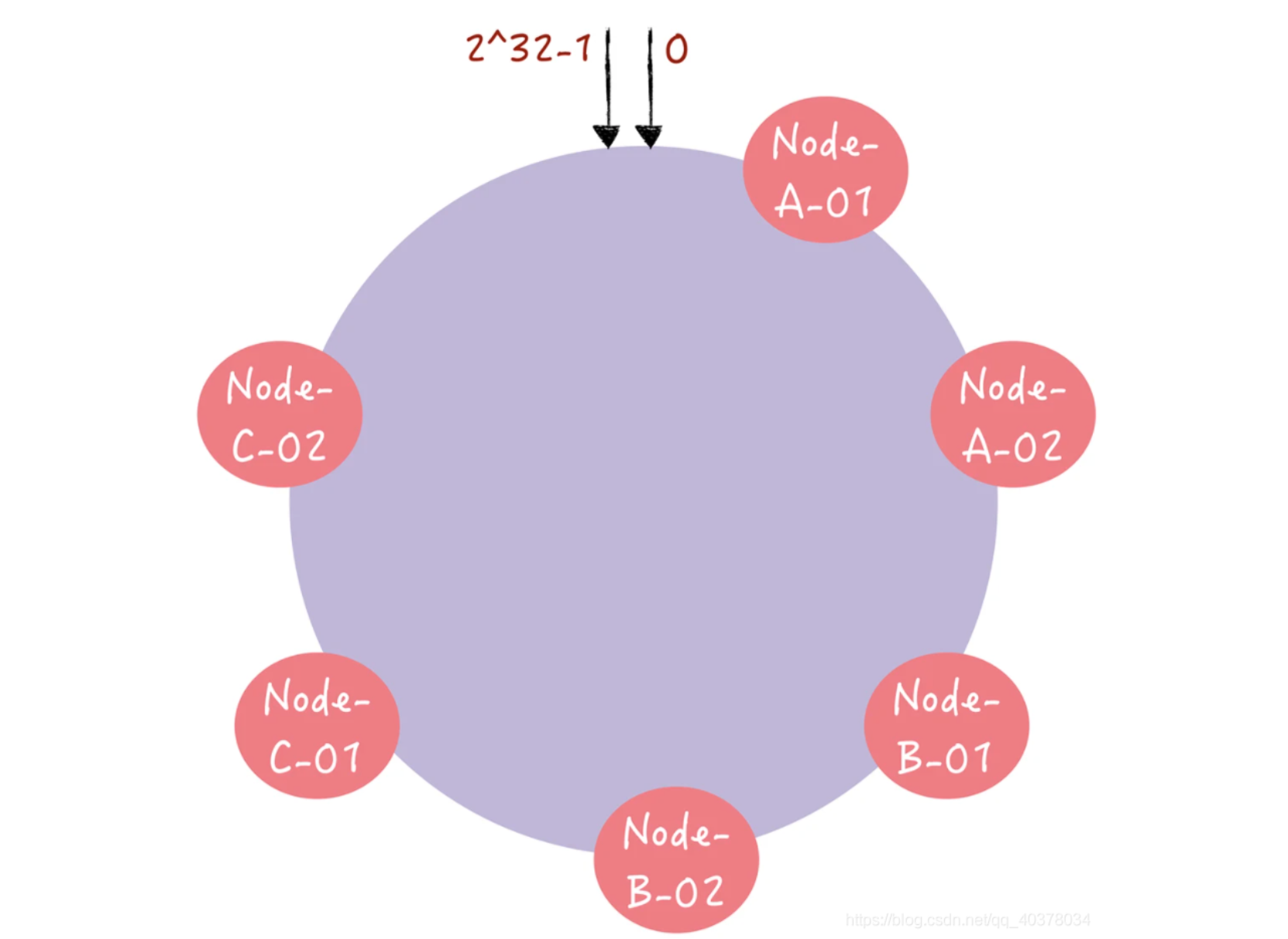
增加了节点后,节点在哈希环上的分布就相对均匀了。如果有访问请求寻址到Node-A-01这个虚拟节点,将被重定位到节点A。
参考:
实现
字段
1 | type Map struct { |
虚拟节点和真实节点的倍数关系
虚拟节点和真实节点的映射关系
方法
Add添加缓存节点
- 虚拟节点名称为序号+key名称
- 循环replicas次,计算虚拟节点的哈希值,进行类型转换
- 添加到哈希环中
- 维护虚拟节点到真实节点之间的映射
- 最后对哈希环排序
Get选择缓存节点
- 校验数据有效性
- 计算key的哈希值
- 顺时针找到哈希环上的第一个匹配的虚拟节点的下标
- 通过hashMap定位到真实的缓存节点
1 | package consistenthash |
总结
- 学习到了什么是一致性哈希,了解了一致性哈希是如何解决数据倾斜的原理。
- 了解了如何通过一致性哈希算法来进行分布式缓存。
参考:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 贾小白博客!
 微信
微信 支付宝
支付宝


