
1-Golang幼麟实验室笔记(切片、字符串、结构体、map)
学习前的介绍
通过幼麟实验室的学习让我更加深刻的去理解Golang的底层原理,看完最深刻的感受就是脑子好痒,非常干,全是干货。自己做的笔记整理出来,方便复习和阅读。
string
Unicode字符编码
变长编码
| 编号 | 编码模板 | 最高位固定标识位 |
|---|---|---|
| [0, 127] | 0??????? | 0 |
| [128, 2047] | 110????? 10?????? | 110 和 10 |
| [2048, 65535] | 1110???? 10?????? 10?????? | 1110 和 10 和 10 |
例如
界 编号:30028——->二进制(01110101 01001100)
将其填如对应的?位置——>得到界UTF-8编码:11100111 10010101 10001100

string的数据结构
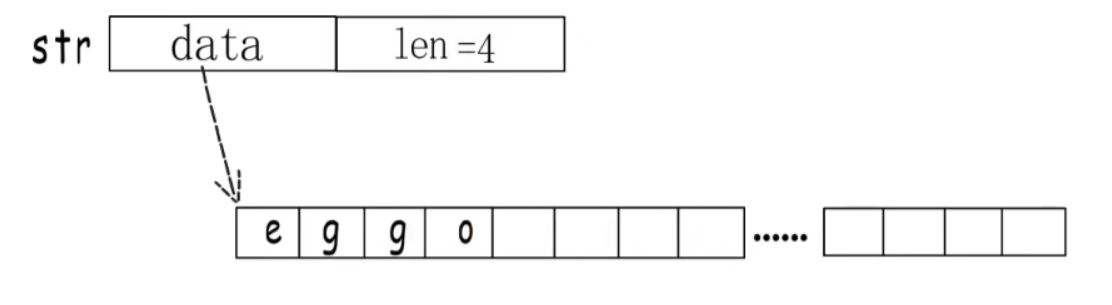
- golang不用特定标识符表示字符串的结尾。
- golang采用string结构体来共同描述一个字符串。
- data是指向字符串开始位置的指针。
- len表示字符串的字节个数(非字符个数),因为golang采用utf8的变长编码方式,故不能采用字符个数。
string的底层细节
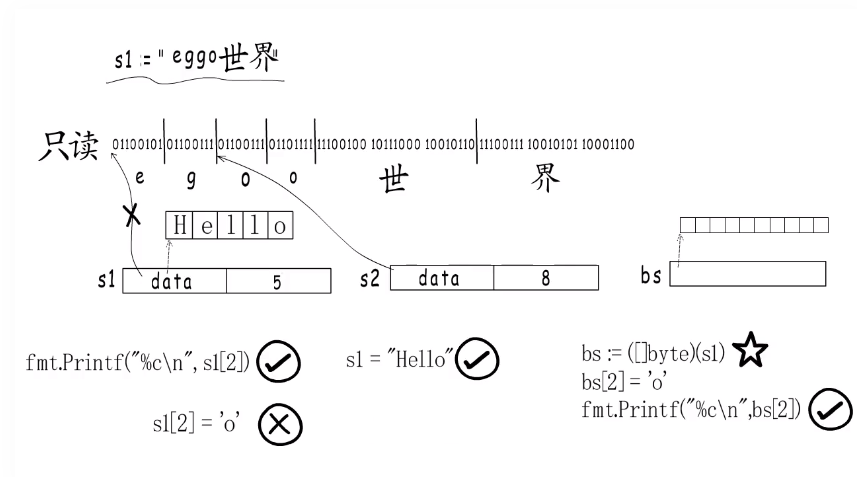
- golang将string类型分配到只读内存段,因此不能通过下标的方式修改。
- s2的起始地址是第3个字节,字节数目是8(起始地址到s1结尾字节数目)
- 多个string变量可以共用同一个字符串的某个部分。(如上图s2:如果s1修改eggo为egoo,那么s2也会受影响)
- 可以给变量整体附新值
s1="Hello",那么s1就会指向新的地址。 - 可转为字节切片对字符串内容进行修改,不过改动的是拷贝后的字符串(上图bs切片)
slice
slice结构
slice分三部分:【存哪里】【存了多少元素】【可以存多少元素】(data, len, cap)
var a []int:变量a —> (data=nil, 0, 0)var a = make([]int, 3, 5)变量—>(data=起始地址, 3, 5)new一个slice
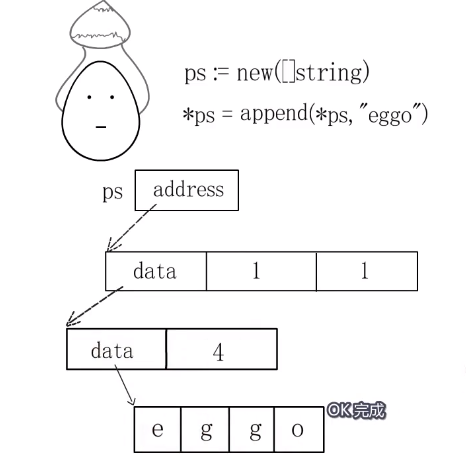
slice扩容机制
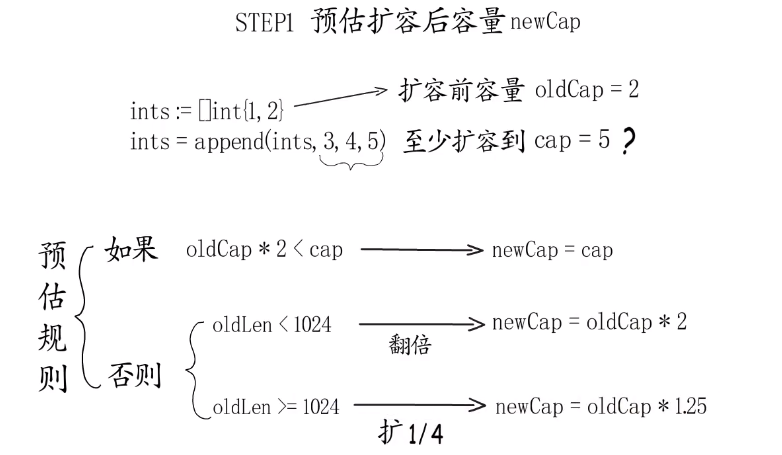
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
扩容之后的数组一定是新的么
- 情况一:切片的cap还够用,则扩容后还是原来的底层数组。
- 情况二:切片的cap不够用,则扩容后会开辟新的数组,将原来的值拷贝后再扩容,此时的底层数组是新开辟的而不是原来的。
如上图中扩容后cap=5后发生什么(假如机器是64位)
- 内存管理模块会提前向操作系统申请一批不同规格的内存地址如(8, 16, 32, 48, 64, 80, 96…)
- 预估申请的内存会匹配到合适规格的内存,5 * 8 = 40byte, 那么就会匹配到规格为48字节的内存。
内存对齐
地址总线和数据总线
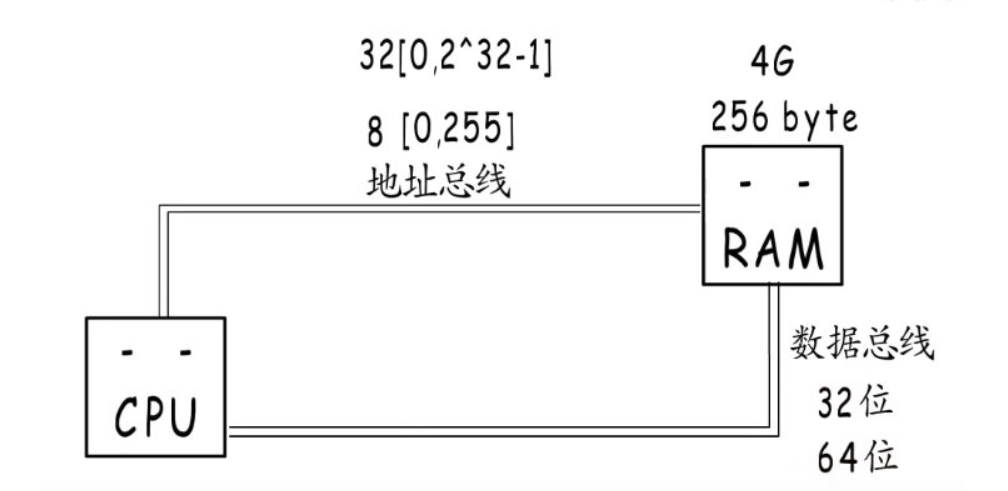
- CPU是通过地址总线来对存储单元进行寻址的,8根地址总线[0,255]可寻址256Byte内存,32根地址总线[0,2^32-1]可寻址4G内存。
- CPU与内存或者其他器件之间的数据传输时通过数据总线来进行的。数据总线的宽度决定了CPU和外界的数据传输速度。8根数据总线一次即可传送8位二进制数据(1个字节);16位即可一次传送两个字节。每次操作的字节数称为机器字长。
内存对齐
现代计算机中内存空间都是按照字节(byte)进行划分的,编译器会把各种类型数据安排合适的地址,并占用合适的长度,这种就称为内存对齐,内存对齐是指首地址对齐。
为什么要内存对齐
- 有些
CPU只能在特定地址访问数据,不同硬件平台具有差异性,在编译时将分配的内存进行对齐,这就具有平台可以移植性了。 CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问,所以数据结构应该尽可能地在自然边界上对齐,如果访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存访问仅需要一次访问,内存对齐后可以提升性能。
现代计算机中内存空间都是按照字节(byte)进行划分的,编译器会把各种类型数据安排合适的地址,并占用合适的长度,这种就称为内存对齐,内存对齐是指首地址对齐。
举个栗子
32 位的 CPU ,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。
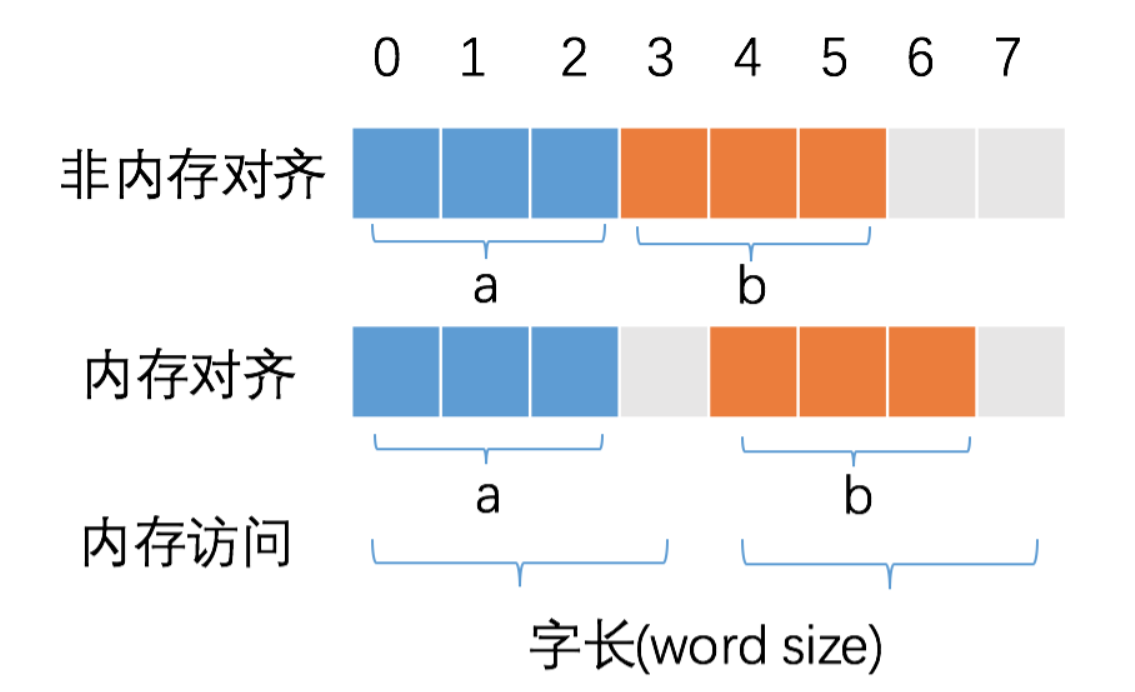
变量 a、b 各占据 3 字节的空间,内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节。
对齐边界
- 每种类型的对齐值就是它的对齐边界。
- 内存对齐要求数据存储地址及占用的字节数都要是它对齐边界的倍数。
取类型大小与平台最大对齐边界中较小的值。

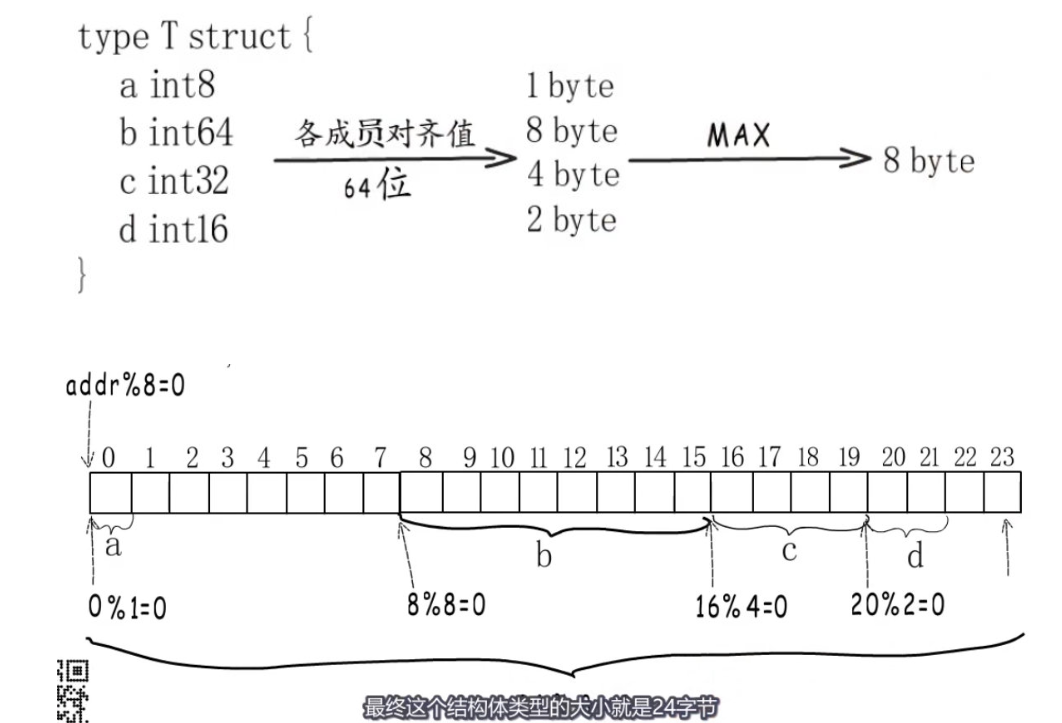
结构体内存对齐
- 结构体对齐边界是成员中最大的对齐边界
- 结构体占用字节数需要是类型对齐边界的倍数
map
map的结构
Go语言中map是散列表的引用。散列表可以用来存储键值对元素。
map类型是map[k]v,其中k是字典的键,v是字典中值对应的数据类型。
1 | var a map[string]string |
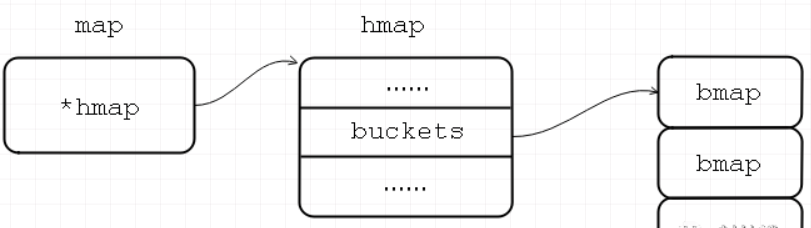
map类型的变量本质上是个指针,这些键值对实际上是通过哈希表来存储的。
Map类型
Go语言中Map类型的底层实现就是哈希表。实现了快速查找、添加、删除的功能。
map类型变量本质上是一个指针,指向hmap结构体。
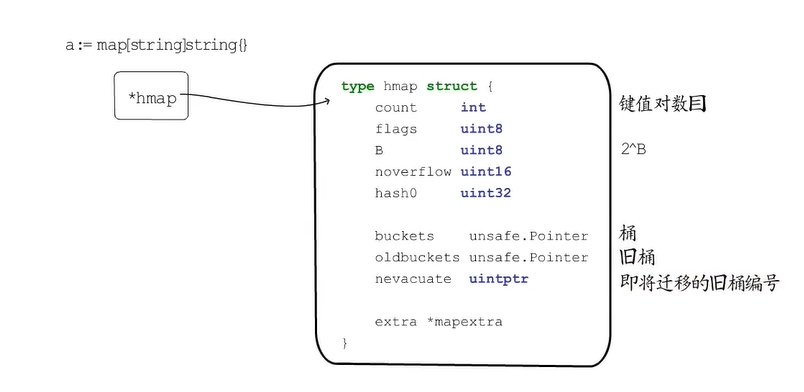
bmap的结构
- 8个tophash:对应hash值的高8位
- 8个key在一起
- 8个value在一起
- bmap类型的指针,指向溢出桶
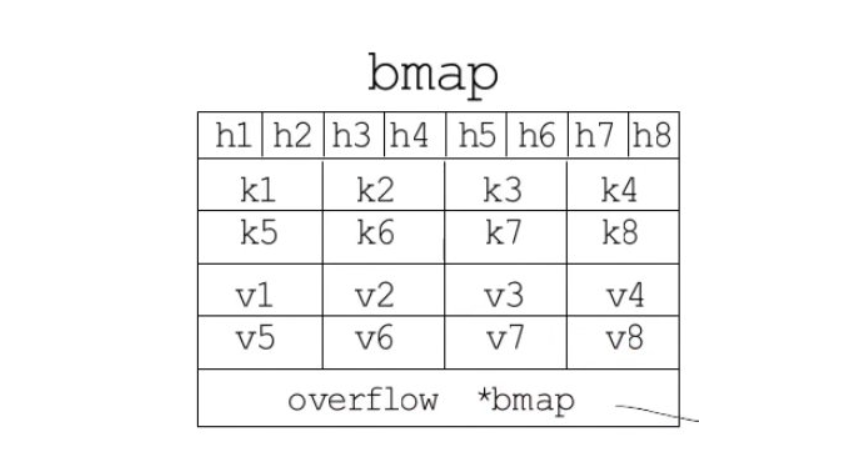
溢出桶
哈希表要分配的桶数目大于2^4时,使用溢出桶的概率较大,会预分配2^(B-4)个溢出桶备用;这些溢出桶与常规桶内存中是连续的,只是前2^4作为常规桶,后面作为溢出桶。
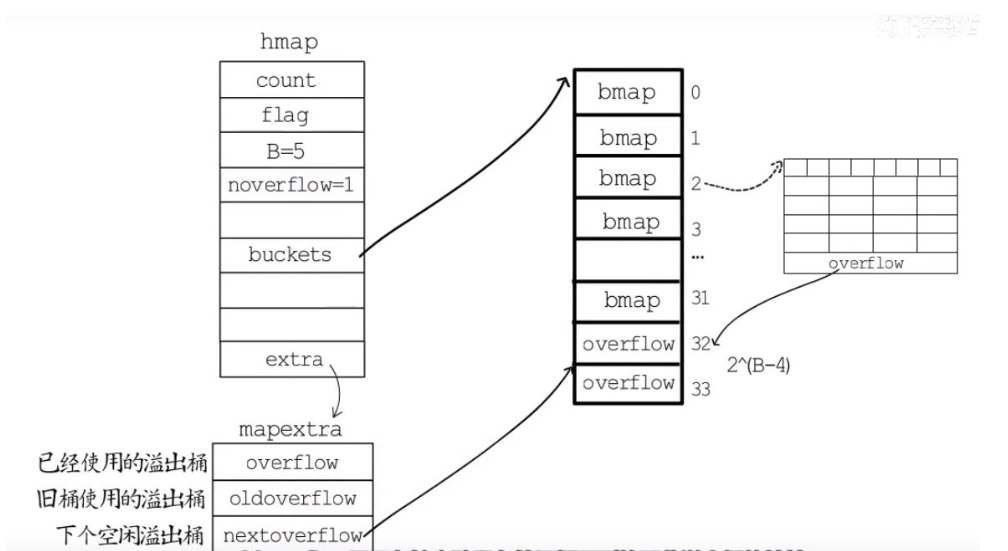
mapextra:溢出桶信息
- overflow:已使用的溢出桶地址
- oldoverflow:旧桶使用的溢出桶地址
- nextoverflow:下个空闲溢出桶地址
常用方法
- 取模法:hash % m
- 与运算法:hash & (m-1) ,注意m需要是2的整数次幂,否则会出现空桶(绝对不会选中)
哈希冲突
- 开放地址法: 当冲突时,查找下一个位置继续判断是否冲突,直到无冲突为止
- 拉链法:冲突时在位置上再建立一条链,存储相应映射到该位置的数据,查找时,也是对于链上元素进行遍历,删除时只需要打上标记,通常不实际进行删除。
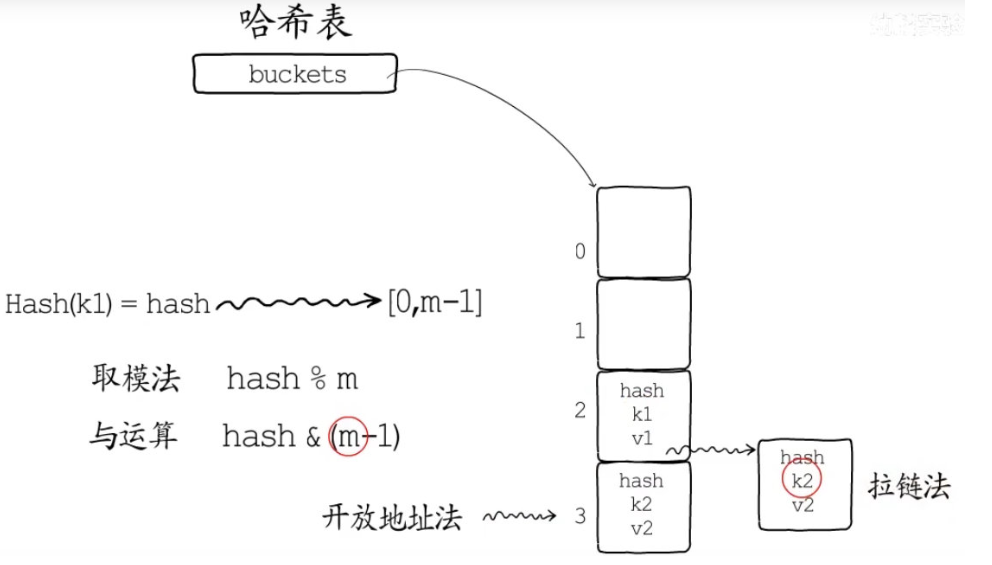
哈希冲突会影响哈希表的读写效率,解决方法:
- 选择散列均匀的哈希函数
- 适时进行扩容
扩容
何时扩容
哈希表中存储的键值对数量和桶数量的比值会作为判断哈希表是否需要扩容的依据,这个依据叫做负载因子(Load Factor)通常需要设定一个触发扩容的最大负载因子。Go语言默认负载因子是6.5。
负载因子 = 填入哈希表中的元素个数 / 哈希表的长度
如何扩容
渐进式扩容:把键值对迁移时间分摊到多次哈希表操作中的方式。可以避免一次性扩容带来的性能瞬时抖动。
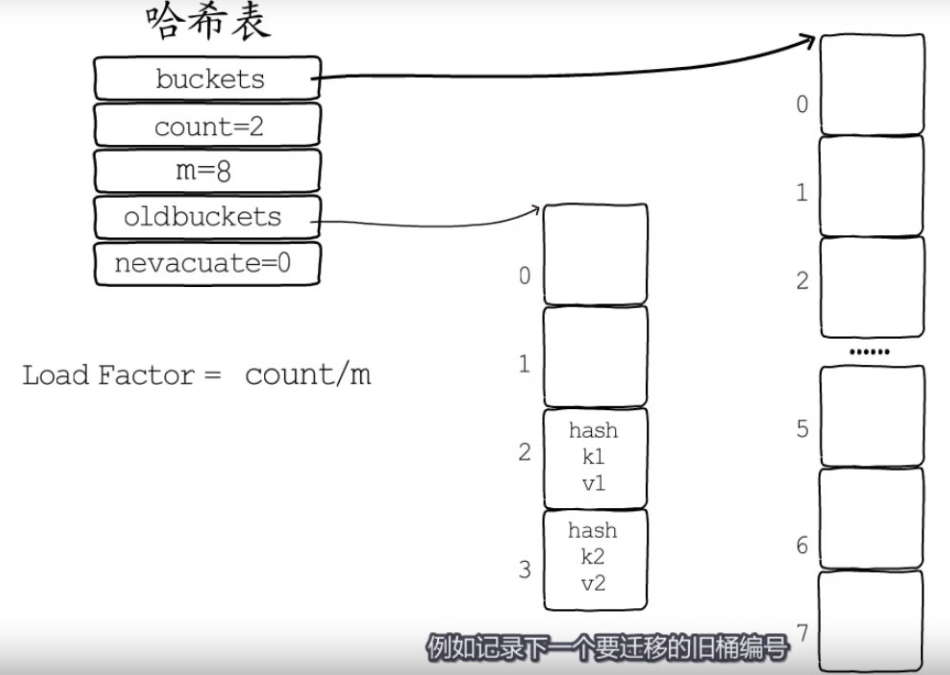
翻倍扩容:Go语言默认负载因子是6.5,超过这个数会触发翻倍扩容
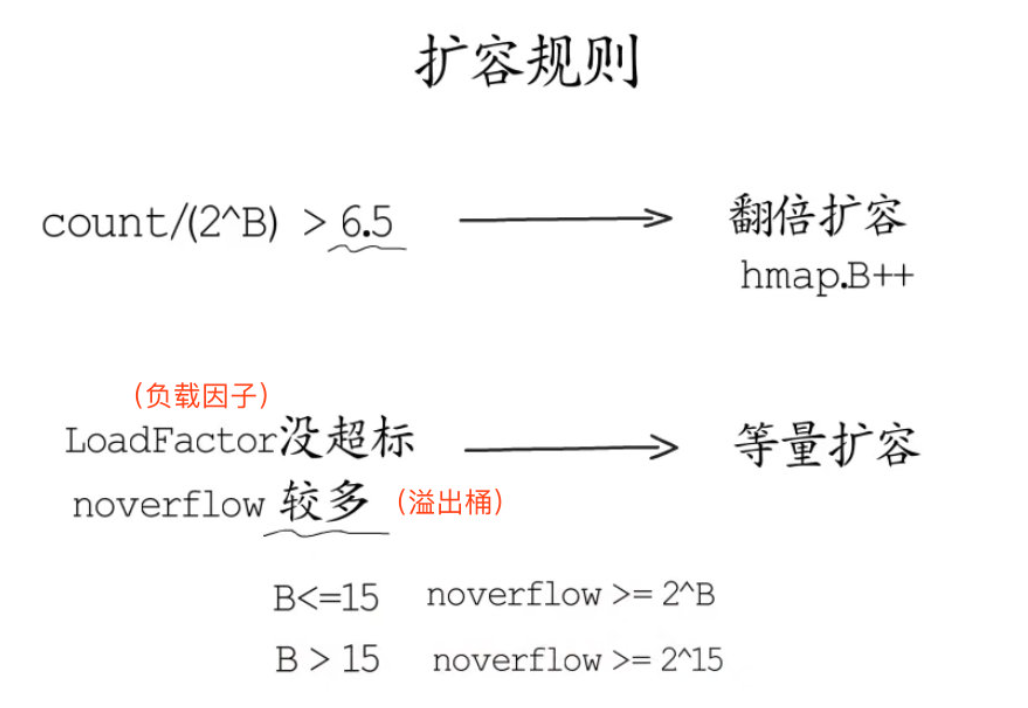
等量扩容:负载因子没有超标,但溢出桶较多,会触发等量扩容。
常规桶数量 = 2 的 B 次方
解释:若溢出桶过多也会触发 map 的扩容, 这是基于这样的考虑, 向 map 中插入大量的元素, 哈希桶将逐渐被填满, 这个过程中也可能创建了一些溢出桶, 但此时装载因子并没有超过设定的阈值, 然后对这些 map 做删除操作, 删除元素之后, map 中的元素数目变少, 使得装载因子降低, 而后又重复上述的过程, 最终使得整体的装载因子不大, 但整个 map 中存在了大量的溢出桶, 因此当溢出桶数目过多时, 即便没有达到装载因子 6.5 的阈值也会触发扩容,其目的是整理map桶。
参考链接
幼麟实验室bilibili:https://space.bilibili.com/567195437/?spm_id_from=333.999.0.0
 微信
微信 支付宝
支付宝

